χ二乗検定の実施例
χ二乗検定は推計統計学において非常に活用されており、主な検定、またその実施例を一部紹介いたします。
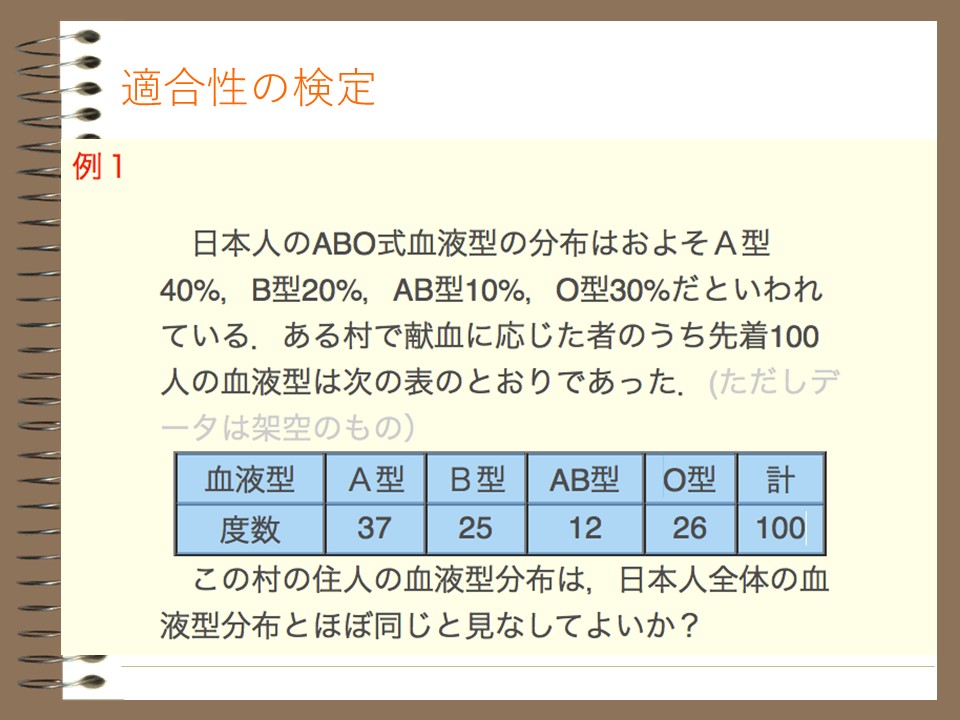
適合性の検定
一つ目は適合性の検定です。
適合性の検定とは調査によって得られたクロス集計表がある場合、実測度数がある特定の分布に適合(一致)するかどうかを検定することです。
以下、例のように日本人における血液型の割合など、既に存在するデータと測定で得られたデータとの間に一致するかを検定することが出来ます。
考え方としては、元あるデータ(期待度数)と得られたデータ(観測度数)を比較する場合において、標準偏差を利用します。標準偏差から推測して、分散を考えることで観測度数と期待度数において数値の大小が偶然によるものなのか考える必要があります。

そこで、各々の差の二乗を各々の期待度数で割ることで、統一して偶然であるかといった割合を求めることが出来ます。この各々の差の二乗を期待度数で割った値をX2と呼び、有意水準5%の境界値と比較することで、ここにおける帰無仮説などを検定することが出来ます。

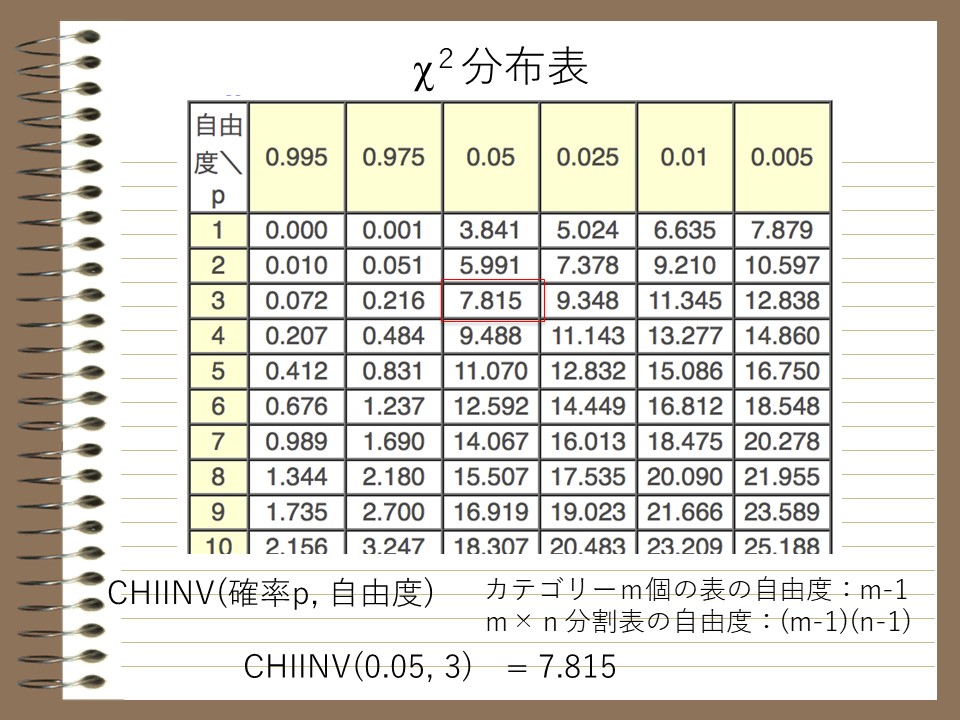
χ二乗の分布表は検索すると多く見つかります。5%の有意水準で検定する場合、以下の表では0.05の列を参照します。また、このケースでは自由度は3なので(4つの選択肢がある場合は、その数字から1を引く)、3行目を参照するといった具合です。エクセルがあればCHIINV関数で簡単に得ることができます。
独立性の検定
二つ目は独立性の検定です。
独立性の検定とは、二つ以上の分類基準をもつクロス集計表において分類基準間に関連があるかどうかを検定することです。
以下、例のように二つのデータ間においてどのような一致が見られるのか、どのような関連性が生じているのかを検定することが出来ます。

考え方としては、二つの方法による結果がそれぞれ方法の違いに影響がないのであれば、得られるデータの割合は等しくなるはずです。つまり、これらのデータを比率的に配分するのであれば、集計のデータを周辺和の比率に配分したものになりえるはずなのです。

よって観測度数と期待度数という風に予めデータを出し、そこから『適合性の検定』と同様にカイ二乗値を求め、有意水準におけるデータと比較することで有意差などを検定することができます。

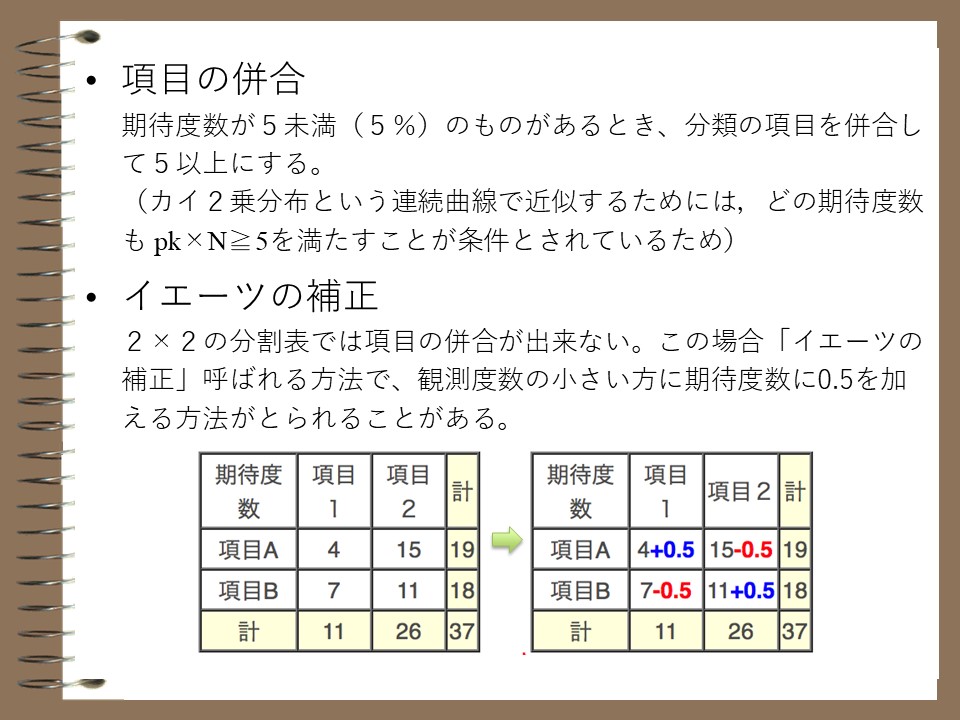
項目の併合や補正
カイ二乗検定をより正確に行うにあたり、前提となる期待度数における条件が存在します。カイ二乗分布という連続曲線において近似するためには、期待度数が5以上である必要があります。期待度数が5未満の時(5%)のものがあるときの対処法としていくつか方法があります。
一つ目は分類の項目を併合して5以上にする方法です。併合が不可能な場合はほかの検定方法を検討する必要が生じてきます。また、併合は前述したように不可能な場合もあり、さらに可能としても細分化していたものを纏めてしまうため、情報量を落としてしまうといった欠点も生じてしまいます。
二つ目はイエーツの補正です。2×2の分割表では項目の併合がむずかしく、このときに活躍するのがイエーツの補正です。検出力は低下してしまいますが、確実にデータを得ることが出来ます。
イエーツの補正を必要とするのは以下の場合です。
・検定をより厳密に行いたいとき
・期待値のデータ表中に5より小さい値が含まれているとき
・データ数が非常に少ないとき